


文:戴学君
一、地产企业信息化中的数据挖掘
地产企业信息化发展历程, 可以划分为四个阶段:
第一阶段:地产企业业务基于信息化技术,实现业务流程化、便捷化、科学化。主要体现在各业务部门基于业务需要,建立各自业务独立的异构系统,实现业务的流程化、电子化。
第二阶段:地产企业业务集中化应用,重在消除信息孤岛,业务平台化应用、数据集中化存储。主要体现在地产企业各地方公司构建数字化管理,基于信息化系统集中整合各种业务应用,实现业务平台化和数据集中存储。
第三阶段:地产企业业务协同化应用,建立区域级数据中心,消除烟囱,实现数据共享、数据挖掘、决策支持。主要体现在地产企业集团,整合各区域公司的信息化应用,实现业务协同、数据共享, 并进行数据挖掘,为决策提供有利支持。
第四阶段:地产企业全区域业务智能化应用,全区域、全单位、全员工共同参与。主要体现在基于云计算、物联网的智能化应用更加深入,环境更加成熟,更全面的满足个性化、多样化的地产企业需求。
目前国内许多大型房企信息化建设已经进入到第三阶段,而第三阶段及第四阶段信息化的核心价值就在地产企业应用数据挖掘。
二 、什么是数据挖掘
数据挖掘是目前国际上数据库和信息决策领域的最前沿研究方向之一,已引起学术界和工业界的广泛关注。如果把知识发现理解为一个过程或系统,数据挖掘就是这一过程或系统的一个可自动执行的工具。数据挖掘包括商业需求、大量的数据和挖掘算法三部分。其中挖掘算法是数据挖掘的重要组成部分。为解决特定的商业问题,一种或多种算法需要被选择、编译,在适于挖掘的数据环境下实施挖掘任务。
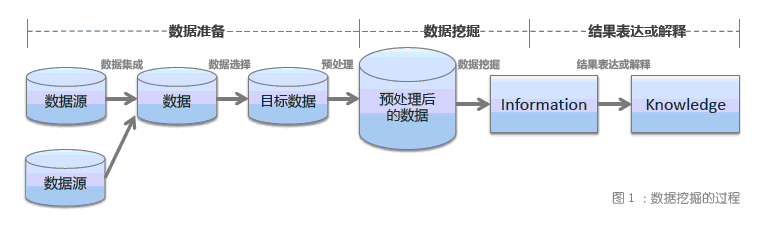
从图1 可以看出,数据挖掘发现是需要人工参与的多环节的过程。数据挖掘涉及人工智能、数据统计、可视化、并行计算等多学科领域,有着多种分类方法。
随着越来越多的地产企业业务需求被不断明确,数据挖掘应用的领域和解决的问题会越来越广泛; 一些地产应用系统,如ERP、SCM、eHR 等系统也逐渐与数据挖掘集成起来,用以提高系统的决策支持能力。这方面的研究热点包括数据挖掘与商业智能(BI)、CRM 等系统的结合。
基于软件进行数据挖掘的发展历程,到现在基于云计算的并行数据挖掘的方式,经历了五个阶段。
第一阶段是单独算法,单个系统,单个机器,而且是向量数据;第二阶段和数据库结合起来,有多个算法;第三阶段跟预测模型更多集成起来,而且它支持Web 数据、半结构化的数据,是一种网络化计算;第四阶段是分布式数据挖掘,时间主要发生在2000 年到2005 年左右,基本上是基于网格计算的概念来做多个算法,分布在多个节点上的方式进行数据挖掘;第五阶段,就是现在基于云计算的并行数据挖掘与服务的模式,同一个算法可以分布在多个节点上,多个算法之间是并行的,多个资源实现按需分配,而且分布式计算模型采用云计算模式,文件数据是用DFS。
三、 云时代海量数据挖掘的背景分析
随着云时代的到来和SaaS概念的引入,越来越多的地产企业开始选择由SaaS应用提供商、运营商等通过互联网平台提供SaaS应用服务,比如CRM云、人力资源云服务(例如赛普的人力资源测评云服务)等,SaaS应用的数据量面临着TB级的增长速度,不同的SaaS应用体系,提供的数据结构也不完全相同,数据有文本、图形甚至小型数据库;SaaS应用数据随着云服务平台的分布性特点,有可能分布在不同的服务器上,如何对这些异构异源的数据进行数据挖掘,也是云时代地产企业所面临的难题。
与传统数据处理不同,海量数据处理是一项更加复杂的工作,存在着容错问题、资源问题、时效问题。
对地产企业而言,如何将各种SaaS应用数据进行整合挖掘,提炼出适合其使用特点的商业信息是地产企业的一大急迫需求。传统的BI模式大多基于数据仓库,是关系型数据库的模式。面对急剧增长的异构数据,传统的数据仓库和原有的并行计算技术由于挖掘效率低,已经不能解决海量数据挖掘工作,影响着数据的及时提取。云时代的地产企业数据挖据面临如下挑战:
(1)挖掘效率:进入云计算时代后,BI的思路发上了转换。以前是基于封闭的地产企业数据进行挖掘,而面对引入互联网应用后海量的异构数据(据预计到2020年,爆发式增长的数据量将突破35ZB,1ZB=10亿TB)时,目前并行挖掘算法的效率很低。
(2)多源数据:引入云计算后,地产企业数据的位置有可能在提供公有云服务的平台上,也可能在地产企业自建的私有云上,如何面对不同数据源进行挖掘也是一个挑战。
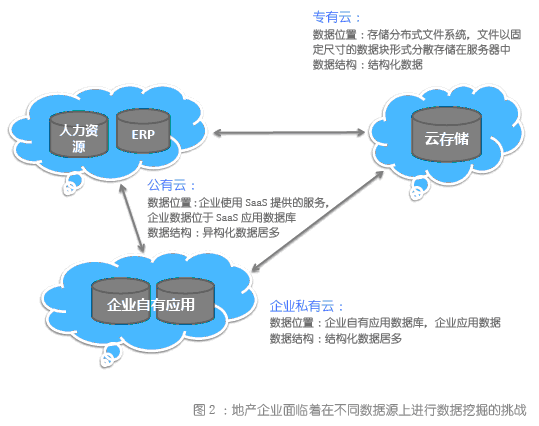
(3)异构数据:Web数据的最大特点就是半结构化,如文档、报表、网页、声音、图像、视频等,而云计算带来大量的基于互联网模式提供的SaaS应用,如何梳理有效数据是很大挑战。
SaaS应用的数据挖掘希望能够通过海量数据存储平台,引入快速并行的挖掘算法,提高数据挖掘的质量。
四、基于云计算进行数据挖掘的好处
从外部特征来看,基于云计算的低成本分布式并行计算环境,对数据挖掘来说,所带来的首要好处就是中小型地产企业的数据处理成本将大大降低,一些地产企业用云计算平台对某些数据的处理,不再依赖于大型高性能机。其次就是开发方便,屏蔽掉了底层。利用云计算平台来做数据挖掘,在并行化条件下,我们利用原有设备使得大规模处理数据能力大为提高,另外可以方便地增加结点,容错性比较强。
五、基于云应用进行数据挖掘的基础设施的选择建议
一直以来,商业智能系统往往基于传统的SMP 架构小型机而构建。随着近年来X86 平台的性能与日俱增、可用性日渐提升、扩展性飞速增长,X86 平台在越来越多的市场领域开始侵蚀小型机份额,商业智能也成为X86 架构向RISC 小型机发起进攻的另一个战场。例如,Oracle 推出的基于英特尔至强平台的Exadata 数据库云服务器, 通过独有的smartscan 技术,以及数据处理过程下移的设计,在X86 架构基础上同时提供了较高的OLAP 性能(数据仓库应用)和OLTP 性能。此外,IBM 也推出了基于X86 平台的商业智能解决方案,基于IBM 独有的EX5 架构服务器和XIV 网格存储系统提供了不输于小型机的智能信息处理能力。
选择建议:
(1)高可用性:BI 的基础架构层,需要建立起数据挖掘云服务平台,而这个平台,必然是高可用性的。
从高可用性来看,需要集中解决两个方面的问题:数据保护和可扩展性。
数据保护, 需要利用CRC、ECC 等硬件机制来对传输的数据进行校验、纠错,如果无法纠正,就将损坏的数据进行隔离,以保证不造成更大的数据,避免系统的重启和宕机。
目前英特尔至强7500 或E7 合作的方案拥有诸多优势,如成本低、性能高、可靠性(RAS)高、可扩展性好等优势。在可扩展性能上,X86 平台横向的向外扩展功能,即由两台以上的机器构成集群。能满足大多数地产企业关键应用环境的负载需求,包括对内存和CPU要求都较高的数据库、商业应用和虚拟化。进而避免传统UNIX双机方案“成本高昂,备机资源平时严重闲置浪费,主机故障切换期间用户服务被迫停顿”等诸多困境。
(2)虚拟化:数据挖掘云服务还是要依赖于虚拟化技术,要计算资源自主分配和调度,也就是说虚拟化技术是数据挖掘云服务技术的支撑。
(3)合适的数据挖掘平台。大数据有很多种不同的使用情况,因此,地产企业需要根据自身业务情况采用不同的的数据挖掘平台。对于那些注重应用分析和处理要求的地产企业客户来说,有很多专门的解决方案,例如惠普Vertica,此外还有很多高性能NAS或者目标系统。
同样地,对于注重视频、安防监控、闭路电视、模拟仿真、大带宽或吞吐量的话,可以考虑惠普Ibrix、戴尔Exanet、BlueArc、HDS、NetApp、Data Direct Networks、Oracle 7000、EMC Isilon和VNX等。
六、适合云应用的数据挖掘的模式建议
(1)数据仓库建模阶段
为了应对SaaS应用大量异构数据,引入XML标记和交换数据。由于XML能够使不同来源的的结构化数据很容易地结合在一起,因而使搜索多样的不兼容的数据库成为可能,从而为解决Web数据挖掘难题带来了希望。XML的扩展性和灵活性允许XML描述不同种类应用软件中的数据,从而能描述搜索的Web页中的数据记录。
引入MapReduce算法,提高数据抽取转换的效率。MapReduce算法是Google提出的一个软件框架,用于大规模数据集(大于1TB)的并行运算。当前的实现方法是指定一个Map(映射)函数用来把一组键值对映射成一组新的键值对,指定并发的Reduce函数用来保证所有映射的键值对中的每一个共享相同的键组。
完善和健壮的低成本开源解决方案是MapReduce最大的特点。比如由Apache基金会开发的Hadoop就是一个这样的开源解决方案,它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。Hadoop是一个分布式系统基础架构,由Apache基金会开发。Apache Software Foundation 公司受到最先由 Google Lab 开发的MapReduce 和 Google File System(GFS) 的启发,在2006 年 3 月份,MapReduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中。
引入HDFS/FastDFS的分布式存储模式。HDFS/FastDFS系统都是分布式文件系统,架构精简,利于提高实施效率,适合海量数据挖掘。都是采用“单一主控机+多台工作机”的模式,通过数据分块和复制来提供更高的可靠性和性能。
引入Hive 架构。Hive 是建立在Hadoop 上的数据仓库基础构架,是一种可以存储、查询和分析Hadoop 中大规模数据的机制, 提供了一系列工具用来进行数据ETL 操作。Hive 定义了简单的类SQL 查询语言,成为HQL,它允许熟悉SQL 的用户查询数据,可以进行复杂的分析工作。
(2)数据挖掘阶段
引入数据分析中间件,提供数据处理、数据探索、数据建模及模型应用等一系列功能,开发多种数据挖据算法和统计建模方法,并能够方便、快捷、高效地处理海量数据,为商业智能的应用提供更方便、更灵活的工具和服务。
(3) 数据呈现阶段
BI 作为云计算的一种SaaS 服务提供给地产企业,建立行业数据库,面对林林总总的SaaS 应用, BI 同样可作为一种SaaS 服务提供给企业。同时数据挖掘工具进行数据分析,可以发现重要的数据模式, 这对构建知识库作出了巨大贡献, 数据和信息之间的鸿沟要求系统地开发数据挖掘工具,将数据“孤岛”、“坟墓”转换成知识“金块”。 基于以上模式建议分析,针对地产企业,我们所设计的数据挖掘模式图如下图3 所示:
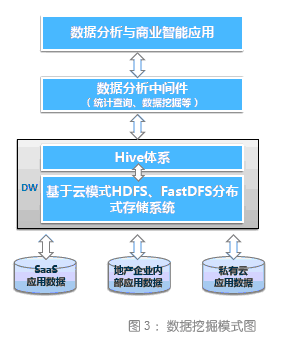
企业数据层:企业数据来源于各类应用,如SaaS 应用、地产企业内部应用数据和专有云应用。
数据仓库层(Data Wareho-use):主要引入HDFS、FasDFS 分布存储系统和Hive 体系架构, 通过MapReduce 算法对数据梳理和提取。
数据挖掘层:引入基于XML 数据分析中间件,实现统计查询和数据挖掘功能。
数据分析和BI 应用层:将BI 以SaaS 服务的模式提供给地产企业使用。
总结
地产企业的数据挖掘云服务将很快兴起,随着云时代的到来,地产企业面临的应用方式更加多元化,通过云的手段提供海量数据挖掘的方法,提高了挖掘的效率,增加了挖掘的精度,更利于挖掘应用的推广以及专业的行业知识库的构建,地产企业数据挖掘应用范围将大大拓宽。高可信的基于云计算的数据挖掘与地产企业云服务是未来的一个重要方向。